

 Bybit
Bybit
 Facebook
Facebook
 WhatsApp
WhatsApp
 Instagram
Instagram
 Twitter
Twitter
 LinkedIn
LinkedIn
 Line
Line
 Telegram
Telegram
 TikTok
TikTok
 Skype
Skype
 Viber
Viber
 Zalo
Zalo
 Signal
Signal
 Discord
Discord
 Kakao
Kakao
 Snapchat
Snapchat
 VKontakte
VKontakte
 Band
Band
 Amazon
Amazon
 Microsoft
Microsoft
 Wish
Wish
 Google
Google
 Voice
Voice
 Airbnb
Airbnb
 Magicbricks
Magicbricks
 Economictimes
Economictimes
 Ozon
Ozon
 Flipkart
Flipkart
 Coupang
Coupang
 Cian
Cian
 Mercadolivre
Mercadolivre
 Bodegaaurrera
Bodegaaurrera
 Hh
Hh
 Bukalapak
Bukalapak
 youtube
youtube
 Binance
Binance
 MOMO
MOMO
 Cash
Airbnb
Cash
Airbnb
 Mint
Mint
 VNPay
VNPay
 DHL
DHL
 MasterCard
MasterCard
 Htx
Htx
 Truemoney
Truemoney
 Botim
Botim
 Fantuan
Fantuan
 Paytm
Paytm
 Moj
Moj
 OKX
OKX
 ICICI Bank
ICICI Bank
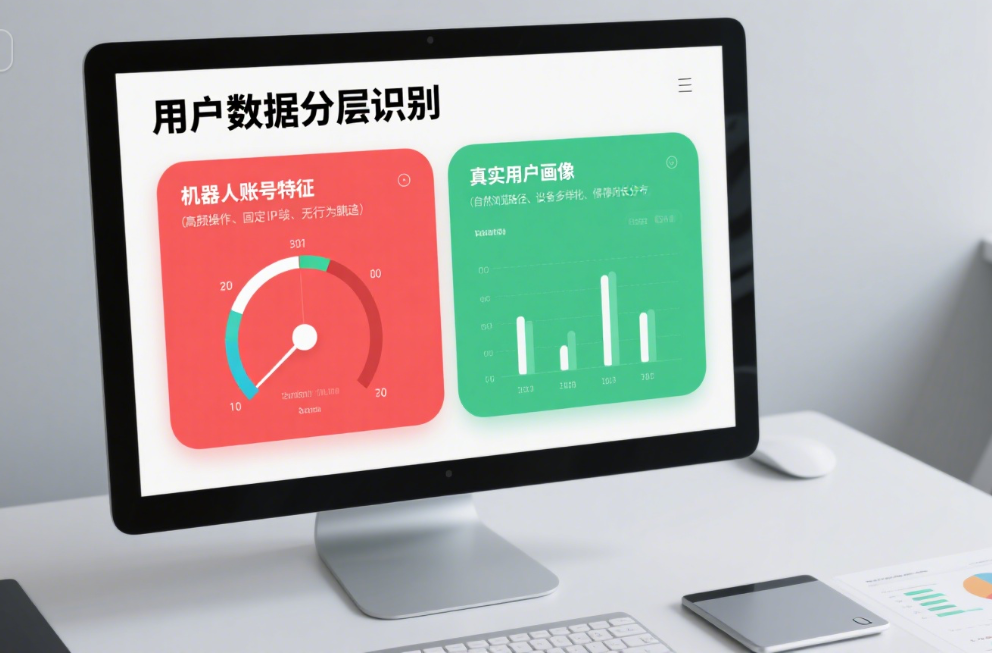
去年负责某社交APP用户增长时,我遇到了职业生涯最头疼的问题——后台数据显示日活用户每月增长20%,但核心功能使用率不升反降。直到技术团队拉出一份「用户行为热力图」,我才惊觉:看似热闹的增长曲线里,藏着35%的「幽灵用户」——它们凌晨3点批量注册,用固定间隔刷取内容,用相同IP地址点赞评论,像一群提线木偶,把我们的用户增长数据「吹」得虚胖。
这让我意识到:在用户增长的战场,「筛除机器人账号」不是「可选项」,而是「必答题」。传统方法如验证码、IP封禁要么误伤率高(我们测试过某验证码服务商,正常用户通过率仅68%),要么机器人能快速绕过(某竞品用OCR破解滑动验证仅需0.8秒)。直到接触「Band筛除模型」,我们才找到平衡「精准拦截」与「用户体验」的关键——它像一把精密的筛子,既能过滤掉90%以上的机器流量,又能让真实用户的流失率控制在1.2%以内。
一、为什么机器人账号是真实用户增长的「隐形杀手」?
很多人对机器人账号的认知停留在「刷量」层面,但实际它们对用户增长的破坏是系统性的。我在分析某教育类APP的用户生命周期时,发现被机器人「污染」的用户池会导致三个致命问题:
1. 数据失真:增长模型跑偏的根源
机器人会模拟真实用户的行为路径,但它们的「互动」是标准化的——比如每注册10个账号,必然在30分钟内点赞5条内容、关注2个账号。这种「完美行为」会让我们的推荐算法误判「用户偏好」,导致优质内容被低质机器人互动推至前列,真实用户反而看不到感兴趣的内容。我们曾监测到,某热点话题下70%的互动来自机器人,导致真实用户对该板块的满意度评分从4.8分暴跌至3.2分。
2. 资源浪费:获客成本的无底洞
为了「维持」虚假的增长数据,企业往往需要持续投入获客成本。以我们当时的投放为例,每获取1个真实用户需要15元,但其中3个注册用户里有1个是机器人——相当于每真实用户成本直接翻倍至30元。更糟糕的是,机器人会占用服务器资源,导致真实用户在高峰时段出现卡顿(我们服务器负载峰值时,机器人请求占比达42%),进一步加速真实用户流失。
3. 生态破坏:社区价值的慢性毒药
在社区类产品中,机器人会直接破坏用户互动的质量。比如某兴趣社区曾出现「水军控评」现象:新用户注册后收到的前10条评论中,8条是机器人发送的广告,导致30%的新用户在7天内流失。我们在用户访谈中发现,超过60%的真实用户表示「讨厌机器人干扰」,其中有18%明确表示「因为机器人太多而卸载APP」。
这些问题让我明白:不解决机器人账号问题,用户增长的所有努力都是「给漏桶加水」。而传统的「头痛医头」式筛除方法,根本无法应对越来越智能的机器人——它们会学习真实用户的行为模式,甚至能通过机器学习生成「拟人化」的操作轨迹。

二、Band筛除模型:从理论到落地的完整框架
「Band筛除模型」是我在参考了Google的Bot Management方案、Facebook的Anti-Spam系统后,结合自身业务场景总结的一套方法论。它的核心逻辑是:**通过多维度行为数据的交叉验证,构建「真实用户」的行为基线,将不符合基线的账号标记为可疑对象,最终实现精准拦截**。这里的「Band」,既指「行为边界」(Behavior Boundary),也指「数据带宽」(Data Bandwidth),强调用动态的、多维度的标准去定义「真实用户」。
1. Band模型的三大核心维度
经过多次迭代,我们将Band模型拆解为「行为一致性Band」「设备环境Band」「社交关系Band」三大维度,每个维度下设置具体指标,形成可量化的评估体系:
| 维度 | 核心指标 | 说明 | 权重 |
|---|---|---|---|
| 行为一致性Band | 操作间隔方差、页面停留时长标准差、功能使用路径熵值 | 真实用户的行为具有随机性,机器人的操作往往过于规律 | 35% |
| 设备环境Band | 设备指纹重复率、IP地理位置跳跃度、浏览器指纹一致性 | 机器人常使用模拟器、代理IP或批量注册设备 | 30% |
| 社交关系Band | 初始关注列表重合度、互动账号活跃度分布、内容传播链复杂度 | 真实用户的社交关系是自然生长的,机器人则倾向于批量关注/互动 | 35% |
举个例子:一个新注册账号,如果「操作间隔方差」小于0.5秒(真实用户平均为2-5秒),「设备指纹重复率」超过80%(同一设备注册超过3个账号),同时「初始关注列表重合度」达90%(关注的账号大部分是新注册的「僵尸号」),那么它会被三个维度同时标记为高风险,进入人工复核或直接拦截流程。
2. 模型的落地步骤:从数据采集到策略迭代
Band模型的落地需要技术、运营、产品的紧密配合。我们用了3个月完成从0到1的搭建,关键步骤如下:
第一步:全量采集用户行为数据
我们埋点了27个关键行为事件,包括「注册来源」「首次点击位置」「页面切换路径」「输入速度」等,每天产生约500GB的行为日志。为了避免数据遗漏,我们特别关注「弱交互场景」——比如用户打开APP后未点击任何按钮的停留时间(机器人常直接跳过)、滑动屏幕的加速度(真实用户有自然的停顿)。
第二步:构建真实用户行为基线
通过分析10万+真实用户的行为数据,我们为每个维度建立了「正常范围」。例如:
行为一致性Band:注册后前30分钟的操作间隔方差在1.2-8.5秒之间;
设备环境Band:单个设备注册账号数不超过2个(排除模拟器);
社交关系Band:新用户首次关注的账号中,活跃用户占比不低于60%。
这里需要注意的是,基线不是「固定值」,而是「动态区间」——我们会根据用户类型(如新用户/老用户)、使用场景(如工作日/周末)调整标准。例如,老年用户群体的「页面停留时长」标准差会比年轻用户大30%,模型会自动识别并放宽限制。
第三步:分级拦截策略
为了平衡拦截效果与用户体验,我们采用「三级拦截」机制:
| 风险等级 | 判定标准 | 处理方式 | 误伤率控制目标 |
|---|---|---|---|
| 高风险 | 任意两个维度指标超出基线200% | 直接拦截注册/限制功能(如仅能浏览) | <0.5% |
| 中风险 | 单一维度指标超出基线150%,或两个维度超出100% | 触发二次验证(如滑动验证码+短信验证) | <2% |
| 低风险 | 所有维度指标在基线±100%范围内 | 正常放行,持续观察后续7天行为 | <0.1% |
第四步:持续迭代优化
模型上线后,我们每周分析「拦截日志」与「用户申诉数据」,发现最初的基线对「老年用户」误伤率较高(达到3.8%)。通过分析他们的行为特征,我们调整了「输入速度」的判断标准(允许更长的输入间隔),并将「页面滚动深度」纳入社交关系Band的辅助指标。调整后,老年用户的误伤率降至0.9%,整体拦截准确率从82%提升至91%。
三、实战案例:某社交平台用Band模型提升30%真实用户留存
去年我们与某垂类社交平台合作,他们的核心问题是「用户增长快但留存低」——月新增用户50万,但30日留存率仅28%。通过部署Band模型,3个月后留存率提升至37%,真实用户日均使用时长增加19分钟。
背景与痛点
该平台的机器人主要集中在「兴趣匹配」场景:机器人批量注册账号,主动添加真实用户为好友,发送广告链接。这些账号的「好友申请通过率」比真实用户高40%(因为真实用户会犹豫是否通过陌生账号),但「后续互动率」几乎为0(发送广告后就不再活跃)。
解决方案:定制化Band模型
我们针对其业务特点,重点优化了「社交关系Band」:
新增「好友申请响应时间」指标:真实用户通常在5-30分钟内回复,机器人则在10秒内秒回;
分析「消息内容特征」:机器人消息的关键词重复率高达75%(如「点击链接」「免费领取」),真实用户消息的关键词多样性更高;
引入「跨场景行为关联」:真实用户会在多个场景(如动态发布、评论区)活跃,机器人则仅集中在「好友申请」场景。
效果验证
模型上线1个月后,我们监测到:
机器人账号拦截率从45%提升至89%;
真实用户的「好友申请通过率」下降12%(因为无效申请减少),但「好友互动率」提升27%(真实用户互动更积极);
30日留存率从28%提升至37%,广告收入因用户体验改善增长18%。
平台负责人反馈:「以前我们总觉得机器人是『增长的助力』,现在才明白它们是『增长的毒瘤』。Band模型不仅帮我们过滤了无效流量,还让真实用户的体验回到了『干净』的状态。」
四、常见误区与避坑指南
在实施Band模型的过程中,我们踩过不少坑,以下是最容易出错的三个环节,供大家参考:
误区1:过度依赖单一维度指标
早期我们曾尝试用「IP地址」作为主要筛除依据,但很快发现:很多真实用户使用公司Wi-Fi(同一IP下有上百个账号),而高级机器人可以使用住宅代理(IP地址与普通用户无异)。后来我们转向「设备+行为+社交」的多维度组合,误伤率直接下降了60%。
误区2:忽视用户的「个性化行为」
有段时间,我们为了提高拦截率,收紧了「操作间隔」的标准(要求间隔≥2秒)。结果大量真实用户(尤其是老年人、残障人士)因输入速度慢被误拦截,投诉量激增。这让我们意识到:**真实用户的行为没有「标准模板」,模型必须包容合理的个体差异**。
误区3:缺乏持续的模型迭代
机器人技术也在进化——我们最初能拦截90%的基础机器人,但3个月后,新型机器人学会了模拟「随机点击」「自然滑动」,拦截率下降至75%。因此,模型必须每周更新一次行为基线,每月引入新的检测指标(如最近的「陀螺仪数据」「屏幕亮度变化」),才能保持有效性。
五、未来趋势:AI时代下机器人对抗的新挑战
随着生成式AI的普及,机器人账号正在变得更「聪明」——它们可以用GPT生成自然的聊天内容,用Stable Diffusion生成逼真的头像,甚至模仿真实用户的语音语调。这对Band模型提出了新的要求:
多模态数据融合:除了文本、行为数据,还需要分析图像、语音、视频等多模态信息;
实时计算能力:新型机器人的响应速度以毫秒计,模型必须在0.1秒内完成风险评估;
隐私保护与合规:欧盟GDPR、中国《个人信息保护法》对用户数据采集有严格限制,需要在「精准筛除」与「用户隐私」间找到平衡。
但我始终相信:只要真实用户的需求存在,机器人就无法完全替代人类的互动价值。Band模型的本质,不是「消灭机器人」,而是「守护真实用户的声音」——让每一次用户增长,都建立在真实的连接与信任之上。
结语
从被机器人账号困扰,到用Band模型实现精准拦截,我深刻体会到:用户增长的本质,是一场「真实与虚假」的博弈。Band模型不是万能的工具,但它教会了我一个关键道理——**真正的用户增长,始于对「真实用户」的深度理解,成于对「无效流量」的精准过滤**。希望这篇文章能为你提供一些启发,让我们一起在用户增长的路上,少走弯路,多留真诚。
- 2025-09-01通过Telegram号码筛选提升用户活跃度与参与度
- 2025-09-01Telegram号码筛选技术如何帮助企业降低营销成本
- 2025-09-01Telegram营销新策略:筛号、群发与频道定制一体化
- 2025-09-01如何通过Telegram号码筛选优化社交网络运营
- 2025-09-01Telegram营销新策略:筛号、群发与频道定制一体化
- 2025-09-01Telegram全球号码筛选功能:开通与高效使用指南
- 2025-06-16Telegram数据筛选在不同行业的应用案例分析
- 2025-06-16避免Telegram筛选误区:常见问题与解决方案
- 2025-06-16如何利用Telegram筛选功能优化社群运营策略?
- 2025-06-16Telegram自动化筛选技术:实现高效用户管理